Language Interpretability Tool (LIT) の紹介
概要
Google Researchが、言語解釈ツール Language Interpretability Tool (LIT) を紹介する論文を出しました。NLPモデルが期待どおりに動作しない場合に、何が問題かを解明するために役立つツールだと記載されていて、便利そうだと思い試しに動かしてみたので、LITの簡単な紹介を記載します。

インストール
GitHubのreadmeの記載のとおり、condaで環境を作ります。
LITはフロントがTypeScript、バックエンドがPythonで作られています。
git clone https://github.com/PAIR-code/lit.git ~/lit cd ~/lit conda env create -f environment.yml conda activate lit-nlp conda install cudnn cupti # optional, for GPU support conda install -c pytorch pytorch # optional, for PyTorch cd ~/lit/lit_nlp/client yarn && yarn build
LITの起動
インスタンスの起動
インスタンス起動用のスクリプトをPythonで作り、ポート指定で起動します。
LITのGitHubリポジトリにいくつかサンプルが用意されているので、まず quickstart_sst_demo を起動してみました。このサンプルは、はじめにfine tuningが走るので、起動までにGPUで5分ほどかかります。
python -m lit_nlp.examples.quickstart_sst_demo --port=5432 [optional --args]
起動したら、http://localhost:5432 にアクセス。
インスタンス起動用のスクリプト作成
インスタンス起動用のスクリプトを作成するには、LITのDatasetクラスのサブクラス、Modelクラスのサブクラスを作成し、そのインスタンスを設定したdictをdev_server.Serverの引数に設定してあげる必要があります。
from lit_nlp import dev_server models = {'foo': FooModel(...)} datasets = {'baz': BazDataset(...)} server = lit_nlp.dev_server.Server(models, datasets, port=4321) server.serve()
Design Overview

Datasetクラス
- lit_dataset.Datasetのサブクラスとして作成.
- spec 関数を定義します. データセットのカラムに対して、適切なType情報を設定して、dictで返す必要があります.
- self._examplesにデータセットをdictのリストとして設定する必要があります
class BazDataset(lit_dataset.Dataset): LABELS = ['0', '1'] def __init__(self, path, split: str): self._examples = [] for ex in load_tfds(path, split=split): self._examples.append({ 'sentence': ex['sentence'].decode('utf-8'), 'label': self.LABELS[ex['label']], }) def spec(self): return { 'sentence': lit_types.TextSegment(), 'label': lit_types.CategoryLabel(vocab=self.LABELS) }
Modelクラス
- lit_model.Modelのサブクラスとして作成
- input_spec 関数を定義します. インプットのカラムに対して、適切なType情報を設定して、dictで返す必要があります
- output_spec 関数を定義します. モデルの予測と追加情報に対して、適切なType情報を設定して、dictで返す必要があります. 追加情報にはAttention HeadsやEmbeddingsなどが設定でき、LITでのComponentsのインプットになります.
- predict / predict_minibatch 関数を定義します. input_specの記載と同一のTypeの入力データに対し、前処理を施してからモデルで予測した値を返す必要があります.
class FooModel(Model): LABELS = ['0', '1'] def __init__(self, model_path, **kw): self._model = _load_model(model_path, **kw) def predict(self, inputs: List[Input]) -> Iterable[Preds]: examples = [self._model.convert_dict_input(d) for d in inputs] return self._model.predict(examples) def input_spec(self): return { 'sentence': lit_types.TextSegment(), 'label': lit_types.CategoryLabel(vocab=self.LABELS, required=False) } def output_spec(self): return { 'probas': lit_types.MulticlassPreds(vocab=self.LABELS, parent='label'), }
LITの機能

Embeddings
EmbeddingsをPCA・UMAPで次元削減した結果を3Dで描画されるエリアです。
インタラクティブに探索できるので、あるクラスだけで絞り込みして他のサンプルと距離が離れているデータを見つけたりするのに使えそう。予測が正しいものを青・間違っているものを赤にした label 1のデータを可視化してみました。

Prediction Score
モデルの予測が表示されるエリアです。
2値分類タスクにおいて、閾値を変動させると Metricsの値やConfusion Matrixの値も連動して変化します。データを選択して詳細をData Tableで見ることもできます。

マスクされた単語予測のタスクにおいて、どの単語をマスクするとモデルは何を予測するのかが確率と共に表示されます。

Span Labelingなどの構造化予測のタスクにおいて、ラベルと予測されたタグが表示されます。

Explanations
モデルの判断根拠の説明に用いられる手法であるLIMEや勾配を用いたヒートマップや、Attention Headの可視化が表示されたエリアです。Data Tableで選択されたデータが表示されます。

Datapoint Generator
以下のアルゴリズムでデータを新しく生成することができます。
- Scrambler: 単語をランダムに並び替える
- Backtranslation: 逆翻訳
- Word replacer: 文字の置き換え
- Hotflip : 分類タスクにいおいて、予測に最も影響をあたえるトークンを、反対の影響をあたえるトークンに変更

Performance
評価指標、混同行列が表示されるエリアです。
予測値のTypeによって自動で表示される指標は決まりますが、カスタマイズすることも可能です. 複数モデルを起動スクリプトで設定しておくとモデルごとに評価指標が表示されます。
データをlabelで切り分けて評価指標を表示させたり、Data Tableで選択したデータだけの評価指標を表示させることができます。

動画
公式から 3 分間のDemo動画が公開されています.
グレンジャー因果検定について
概要
仕事でグレンジャー因果検定を使う機会があったので、グレンジャー因果検定について勉強したことを記載します。また、statsmodelsのAPIを使い、株式データを使って簡単な検定をしてみました。
間違いがありましたら、コメントいただけたら嬉しいです。
グレンジャー因果検定
考え方
時系列データ ,
において、
が増減すると
も同じように増減するという関係なのかを検証したい。
未来の の値の予測に、現在と過去の
の値を使って予測した時より、
の値も加えて予測したほうが精度が改善される時、
から
にGrengerの意味で因果があるという。
モデルにVARを利用し、F検定で統計的有意性の検定します。

確かに が増減したら
も同じように増減する関係なら、
の予測に
の値も知っているモデルの方が精度が高く、その逆も言えると考えるのは感覚的も理解しやすいです。しかし、一般的に変数が多ければモデルの精度は高くなりやすいので、それが統計的有意性があるかを調べる必要があり、それを2つのモデルの誤差の比が十分に大きいかF検定で調べます。
ARモデル(自己回帰モデル)
グレンジャー因果検定で使うVARモデル(ベクトル自己回帰モデル)を理解するために、ARモデル(自己回帰モデル)を理解する。
AR(p)モデルは、 時点での
の値を
期内の
の過去値の加重和で表現したモデル。
は定数項、
は自己回帰係数、
はホワイトノイズ(期待値0, 分散
を持ち、自己共分散0の誤差項)。
()
(正確にはは実数に値をもつ確率変数)
VARモデル(ベクトル自己回帰モデル)
VAR(p)モデルは、AR(p)モデルをベクトルに拡張したもの。 と
は
の列ベクトル、
は
の行列。
()
(正確には は実n次元数ベクトルに値をもつ確率変数ベクトル)
例えば、下記のようなVAR(2)モデルは
下記のように書き換えられる
検定方法
考え方で記載したとおり、 を予測するとき、
の値を含めた方が精度が高い、つまり
のほうが
より誤差が小さいことを示したい。
から
にGrengerの意味で因果がないことを帰無仮説とし、2つのモデルの誤差を使いF検定で帰無仮説を棄却する流れになる。
上記の式だと、 (
の係数が
)と同値になる。
F検定統計量は、式 (a) をOLSで推定した時の誤差(残差平方和) と、式 (b) をOLSで推定した時の誤差(残差平方和)
を使って以下のように表され、
は漸近的にカイ2乗分布 (
) に従うので、
の値が
の95%点より大きければ帰無仮説を棄却できる。
ここで は制約(xの係数を0とする制約)の数、
はサンプル数。
F検定
F検定では2つの分散の比がF分布に従うかを調べることで、帰無仮説を母分散が等しい(2つの分散に差がない、今回の場合は2つのモデルの誤差に差がない)、対立仮説を母分散が等しくない(2つの分散に差がある、今回の場合は2つのモデルの誤差に差がある)として、検定を行います。
上記の説明ではF検定統計量を使用していますが、以下の例に記載するstatsmodelsの例ではp値を使用し、p値が0.05未満であれば有意水準5%で有意であり帰無仮説は棄却するとして、検定を行います。
注意点
サンプル数が多い時
単純にサンプル数が多ければ多いほどp値は小さくなりやすいので、サンプル数が多い時はp値に惑わされないよう注意する必要があるようです。
交絡因子について
交絡因子(間接的に影響する変数)が存在していても「Grengerの意味で因果がある」となる可能性があります。因果関係を調べるには、十分ではないことに注意する必要があるようです。
株式データを使って検定
statsmodelsのグレンジャー因果検定
statsmodelsに、grangercausalitytestsが用意されているのでそれを使い、データはkaggleのdatasetのS&P500のデータを使います。
- statsmodels ドキュメント: statsmodels.tsa.stattools.grangercausalitytests — statsmodels
- Kaggle Dataset : S&P 500 stock data | Kaggle
株に関しては完全に素人なのですが、単純に前日の市場が開いてる間に値上がりすれば(前日終値 - 前日始値 > 0)買いな株と判断され、前場の寄り付き前に値上がりして、当日の始値は前日の終値より高いじゃないか(当日始値 - 前日終値 > 0)、逆に前日に値が下がったら、寄り付き前に値下がるのじゃないかと考え検証してみます。
値上がり金額 を とし、始値と前日終値との差を
とした時、
から
へGrengerの意味で因果があるかを調べます。
grangercausalitytestsの第一引数にはarray_likeなデータを指定しますが、
The data for test whether the time series in the second column Granger causes the time series in the first column.
と書かれている通り、1番目のカラムには結果側のデータ 、2番目のカラムには起因側のデータ
となっている配列を指定します。今回は前日の値上がり金額に対して検証したいのでmaxlagを1にします。
import pandas as pd from statsmodels.tsa.stattools import grangercausalitytests import matplotlib.pyplot as plt pd.options.plotting.backend = "plotly" PATH = '/kaggle/input/sandp500/individual_stocks_5yr/individual_stocks_5yr/' # Exxon Mobil Corporation のデータ XOM = pd.read_csv(f'{PATH}/XOM_data.csv', index_col='date', parse_dates=True) # 期間を限定 XOM = XOM[(XOM.index >= pd.to_datetime('2017-07-01')) & (XOM.index <= pd.to_datetime('2017-12-31'))] # 終値と始値の差 XOM['price_increase'] = XOM['close'] - XOM['open'] # 始値と前日終値との差 XOM['before_opening'] = XOM['open'] - XOM['close'].shift() # データ確認 XOM.head() XOM[['price_increase', 'before_opening']].plot() # グレンジャー因果検定の結果取得 x = XOM[['before_opening', 'price_increase']][1:].values results = grangercausalitytests(x=x, maxlag=[1], verbose=False) print(results)


>> {1: ({'ssr_ftest': (2.137422914716022, 0.14633552782619325, 121.0, 1),
'ssr_chi2test': (2.190416871279229, 0.1388717255785229, 1),
'lrtest': (2.171295251305196, 0.1406077610113857, 1),
'params_ftest': (2.137422914716034, 0.14633552782619272, 121.0, 1.0)},
[<statsmodels.regression.linear_model.RegressionResultsWrapper at 0x7f86b1e70c10>,
<statsmodels.regression.linear_model.RegressionResultsWrapper at 0x7f86b1e87d90>,
array([[0., 1., 0.]])])}
4つのタイプで検定された結果が返ってきます。lagのkeyに対して、各検定の結果が格納されています。検定名がkeyで、valueは1番目の要素に検定統計量、2番目の要素にp値が入ってます。params_ftestとssr_ftestはF分布に従うとした場合の検定、ssr_chi2testとlrtestはカイ2乗分布に従うとした場合の検定です。
全ての検定でp値が0.05を大きく上回り帰無仮説が棄却されませんでした...やはりそんな簡単な話じゃなさそうですね😇
例えば、前日に値上げされたら、当日の始値と前日の始値の差はプラスになりそうです。前日終値が前日始値よりすでに高いので。値上げ金額を とし、始値と前日始値との差を
とした時であれば、
から
へGrengerの意味で因果がある、となりそうなので、検定してみます。
# 値上がり金額 XOM['price_increase'] = XOM['close'] - XOM['open'] # 始値と前日始値の差 XOM['diff_open'] = XOM['open'] - XOM['open'].shift() XOM[['price_increase', 'diff_open']].plot() x = XOM[['diff_open', 'price_increase']][1:].values results = grangercausalitytests(x=x, maxlag=[1], verbose=False) results

>> {1: ({'ssr_ftest': (168.13795446547945, 1.220451046664481e-24, 121.0, 1),
'ssr_chi2test': (172.30666408032607, 2.3194627990098294e-39, 1),
'lrtest': (108.01805908422944, 2.663402872664279e-25, 1),
'params_ftest': (168.13795446547954, 1.2204510466644514e-24, 121.0, 1.0)},
[<statsmodels.regression.linear_model.RegressionResultsWrapper at 0x7f86b1e87a90>,
<statsmodels.regression.linear_model.RegressionResultsWrapper at 0x7f86b1f10e90>,
array([[0., 1., 0.]])])}今回は4つの検定でp値が0.05を大きく下回ったため帰無仮説を棄却し、Grengerの意味で因果があると言えそうです。
おわり
株価での検定はあまり良い例が浮かばず、無理矢理感がありました...(本当は、この銘柄が上がると数日後にこの銘柄も上がるかも、みたいなペアを見つけたかった)。ただ株式データでデータ分析するのは面白そうだと思ったので、時系列データについて勉強を進めたらまた触ってみたいと思いました。
F分布周りは完全には理解できてないので、統計検定の勉強を進めながら理解していきたいです。
確率予測とCalibrationについて
概要
確率予測とCalibration(キャリブレーション)に関する勉強会に参加したので、学んだことの一部と、自分で調べてみたことについてまとめました。
- 概要
- Calibrationとは
- Calibration Curve
- Calibrationの方法
- 確率予測に使われる評価指標
- コード
- 不均衡データに対するCalibration
- LightGBMにCalibrationは不要か
- NNにCalibrationは不要か
- 追記 : Calibrationの検討について
- 追記 : 発表スライドについて
- 終わり
勉強会で使われていた言葉を、自分なりの言い方に変えています。
間違いがありましたら、コメントいただけたら嬉しいです。
Calibrationとは
普通の分類問題では、どのクラスに属するかを判別するモデルを作りますが、あるクラスに属する確率はどのくらいか、を予測したい場合を考えます。( 降水確率や広告のCTRなどを予測したい場合など )
モデルの出力値を各クラスに属する確率に近づけること ( モデルの出力値を正解ラベルのクラス分布に近づけるということ ) を、Calibration(較正)と言いいます。
イメージ
| モデルの出力値 | 正解ラベル | Calibrationした値 |
|---|---|---|
| 0.4 |
1 |
0.5 |
| 0.4 |
0 |
0.5 |
0.9 |
1 |
1.0 |
| 0.9 |
1 |
1.0 |
この記事では、確率予測という言葉を、そのクラスに属する確率の予測という意味で使います。
Calibration Curve
Calibration Curveは、確率予測の信頼性を可視化したものです。
作り方は、データを予測値でビニングし、ビニングしたデータの予測値の平均と、それに対応するPositiveデータの出現率でプロットします。
以下の図はCalibration Curveを使い、各モデルの出力値が、確率予測としてどれくらい良いかを表しています。

黒い点線に近いほど、確率予測として信頼度が高いと言えます。ただし、ビン数やどのようにビニングするか(値で区切るか、個数で区切るか)でグラフが変わってしまうことに注意です。
Calibrationの方法
Calibrationの方法を2つ記載します。
Sigmoid / Platt Scale
説明変数をモデル出力値、目的変数を正解ラベルとしてSigmoid関数にフィットさせ、そのSigmoid関数に通した値をCalibrationした値とします。
上記式における と
は勾配降下法などで求めます。
scikit-learnのSigmoid Calibration実装
https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/calibration.py#L392
この方法は、Calibration CurveがS字になるようなものに有効で、scikit-learnには線形SVMの例が記載されていました。

SVMはマージンを最大化して境界部分を厳しく判別するというモデルの性質から、予測値が 0.5 付近に集中します。それを改善するためにSigmoid関数にフィットさせて0.5 付近を平すというのは直感的にもわかりやすいです。

Isotonic Regression
ノンパラメトリックな手法として、Isotonic Regressionがあります。
Isotonic Regressionは、Isotonic関数 (単調増加)を使い以下のように表せます。
Isotonic Regressionのアプローチの1つにPAV (pair-adjacent violators) という方法があります。
データを予測値でソートし、隣接ペアで予測値と正解ラベルとの順序関係を保つように、調整された値を計算していく方法です。

https://www.cs.cornell.edu/~alexn/papers/calibration.icml05.crc.rev3.pdf
PAVは計算量が となるため、scikit-leranの実装では、Active set algorithms for isotonic regression; A unifying frameworkに記載されている計算量が
の方法で、Isotonic Regressionを実装しているようです。
link.springer.com
scikit-leranの Isotonic Regression 実装部分
https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/isotonic.py#L134
Naive Bayes を Isotonic Regression で Calibrationした例がscikit-leranに記載されてました。

確率予測に使われる評価指標
確率予測でよく使われる指標を調べてみました。
ECE
データをビニングして、そのビン内での精度と信頼度の差を加重平均したもの。予測クラスと確率予測値の両方が必要。
: ビン数
: 全体のサンプル数
: ビン内のサンプル数
: accuracy ( 精度 )
: 確率予測値の平均( 信頼度 )
コード
scikit-learnに CalibratedClassifierCV があり、引数 method に "sigmoid" か "isotonic" を指定しすることで scikit-learn 準拠モデルで使用できます。
引数 cv に "prefit" を指定すると、すでにbase_estimatorが適応されているモデルとみなされます。
from sklearn.calibration import CalibratedClassifierCV, calibration_curve from sklearn.svm import LinearSVC from sklearn.metrics import brier_score_loss import plotly.graph_objects as go clf = LinearSVC() cl_clf = CalibratedClassifierCV(clf, cv=3, method='sigmoid') cl_clf.fit(X_train, y_train) # calibracationされた値を取得 prob_pos = cl_clf.predict_proba(X_test)[:, 1] # 評価 clf_score = brier_score_loss(y_test, prob_pos) print("Brier Score: %1.3f" % clf_score) # calibration curve fraction_of_positives, mean_predicted_value = calibration_curve(y_test, prob_pos, n_bins=10) fig = go.Figure(data=go.Scatter(x=mean_predicted_value, y=fraction_of_positives)) fig.show()
不均衡データに対するCalibration
不均衡データをUndersamplingした場合、サンプル選択バイアスが生じ、少数派クラスの確率が大きくなってしまいます。なのでCalibrationして、バイアスを除去します。
この場合のCalibrationは上記に記載したような Sigmoid や Isotonic Regression を使った方法ではなく、以下のような式を使います。
: Undersamplingして学習した時の予測値
: Undersampling率を
実際の例がこちらのブログに記載されていました。
pompom168.hatenablog.com
https://www3.nd.edu/~dial/publications/dalpozzolo2015calibrating.pdf
追記
こちらに関して、発表者の方からコメントを頂いております。合わせて確認いただけたらと思います。
LightGBMにCalibrationは不要か
上記にSVMやNaive Bayesの例を記載しましたが、LightGBMに関してはどうなのでしょうか。
ちなみに、同じ木系でもRandom Forestの場合は、バギングというアンサンブルの性質から予測値が 0, 1 付近ではなく、それより少し離れたところに多く集中してしまうため、Calibrationが必要です。(バギングで限りなく 0 付近、限りなく 1 付近の予測値を出すには、各木がほとんど間違えずに予測する必要があるため)
Random Forestの予測値分布

しかし、LightGBMはブースティングなのでこれとは異なり、Log Lossを最適化することでcalibrateされるとの考察をいくつか見つけました。(それでモデルが自信過剰・自信不足になっていないと言えるのか、私には確信が持てなかったので詳しい人がいたらコメントいただけたら嬉しいです...)
追記
こちらに関しても、発表者の方からコメントを頂いております。合わせて確認いただけたらと思います。
NNにCalibrationは不要か
同じように、NNではどうなのか?という疑問ですが、こちらの論文を見つけました。
この論文では、最近のNNは自信過剰 (0, 1に近い) で、Calibration が不十分であると記載されていました。
追記 : Calibrationの検討について
ブログを公開したところ、ありがたいことに以下のようなツイートをしていただけました!
確かに、train, val, test のそれぞれの予測値/目的変数の平均と分布を見て、Calibrationの必要性を総合的に判断するのが良さそうです。
個人的には
— にのぴら (@nino_pira) 2020年5月25日
- val / testの予測値の平均値とtrainの目的変数の平均値を見て一致しているかを確認
- train / val / testの予測値の予測値の分布を見る
2点をやって、なんかヤバそうだったらcalibrationを検討していますhttps://t.co/dujyDeGtTi
追記 : 発表スライドについて
勉強会で発表された資料が後日公開されたので、紹介いたします。
冒頭でも記載したとおり、本ブログは、こちらの発表内容の一部と、そのあと自分で調べた内容を記載したものです。以下の資料はCalibrationに関してより詳しい説明が記載されている資料となります!合わせてご確認いただけたらと思います。
終わり
勉強会では分類全般における評価指標の比較についても言及されていて、とても面白かったので、またそのあたりについても記事を書きたいです。
オンラインで色々な勉強会に気軽に参加できるのは、引きこもり生活の中で非常にありがたいと感じました。
画像の半教師あり学習について整理した
概要
勉強会で画像の半教師あり学習について取り上げられるたびに、あれ、これ似たやつなかったっけ?と混乱するので、整理してみました。同じような内容のネット記事や資料はありますが、自分のために記載します。
半教師あり学習とは
半教師あり学習 (Semi-supervised learning: SSL) とはラベル付きデータとラベルなしデータで学習を行う方法。ラベルなしデータを活用してモデルのパフォーマンスをあげます。
MixMatch
MixMatchという半教師あり学習のアルゴリズムについて記載します。画像の分類問題を想定しています。

- ラベル付きデータ
に対しData Augmentationで変換したデータ
を作る
- ラベルなしデータ
に対し
種類のData Augmentationで変換したデータ
を作る
- ラベルなしデータで予測値 (モデルの出力値) を取得し、予測値平均
を計算する. ( 1 サンプル
- Sharpen関数を用いて、予測値
を取得する.
・は温度(ハイパーパラメータ)
とラベル付きデータ
を合わせて
のデータセットを作る
を作る
を作る
とする
とする
- モデル全体の誤差は、
として学習する (
はハイパーパラメータ)

[論文] MixMatch: A Holistic Approach to Semi-Supervised Learning
[1905.02249] MixMatch: A Holistic Approach to Semi-Supervised Learning
MixUp
MixMatchで使われるMixUpにいついて記載します。
Data Augmentation の一種です。
- トレーニングデータからランダムに2つのサンプル、データとラベルを取り出す
- データもラベルも以下のように混ぜて新しいデータを作成する
(はベータ分布からサンプリングした値)
[論文] mixup: Beyond Empirical Risk Minimization
[1710.09412] mixup: Beyond Empirical Risk Minimization
ReMixMatch
ReMixMatchは、MixMatchをさらに2つの新しいテクニックで改良した、半教師あり学習の方法です。
Distribution Alignment
1 つ目のテクニックは、ラベルなしデータの推論ラベル (モデルの出力値) の分布を調整する Distribution Alignment です.
MixMatchの中で、ラベルなしデータの推論ラベル にSharpen関数を用いる処理がありますが、その直前に以下の式で推論ラベル分布をデータセットのラベルの分布と同じになるように正規化します。
下の図と対応させると、 がラベルなしデータの推測ラベル (label guess) で、
が真のラベル (Ground-Truth labels) で、
がラベルなしデータの推測ラベルの移動平均(Model predictions). 移動平均は直前の128バッチの推測ラベル.

Augmentation Anchoring
2 つ目のテクニックは、Data Augmentationの強さの調整、Augmentation Anchoring です。
推論ラベルを取得するための、モデルのinputとなるラベルなしデータに対しては、弱いData Augmentationをかけます。下の図で言うと緑の部分。 実際に学習で使うデータ(MixUpで使うデータ)は、強い 種類のData Augmentationで変換したデータです。下の図で言うと青の部分。

また、この強いData Augmentationには、CTAugmentという手法を使います。
CTAugment
Data Augmentation の変換種類はランダムで決めますが、その強さ (変換用パラメータの値) が学習中に動的に調整されます。
- Data Augmentationにおける変換用パラメータの値をそれぞれ n 個にビニングします。
- ビニングされたパラメータの値に対応する各 weight をベクトル
として表します
- Data Augmentationのタイミングで、2種類の変換が選ばれます。変換用パラメータの値 はこの
- weightの更新の方法は、モデルの予測とラベルがどの程度一致するかを以下の式で表し、その一致度を使って更新します。
一致度
更新式(
= 0.99 )
[論文] ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring:
[1911.09785] ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring
FixMatch
FixMatchはPseudo-LabelとConsistency Regularizationを使った半教師あり学習です。
Pseudo-Label
弱いData Augmentationで変換した画像をモデルのinputにして、出力の中で確信度の一番高いラベルでハードラベリングし、Pseudo-Label (疑似ラベル)とします。
Consistency Regularization
Consistency Regularizationとはラベルなしデータの画像にノイズを加えても、モデルの出力値が変わらないようにする方法です。一般的には以下のような項をLoss関数に付け加えます。
FixMatchでは、Pseudo-Label と強い Data Augmentation をかけたデータのモデル出力値を使ってConsistency Regularization を行います。

全体的なアルゴリズムは以下のとおりです。
- ラベルありデータのLoss関数
は通常のクロスエントロピーLoss関数
です。
・は弱い Data Augmentation
・はラベル
- ラベルありデータのLoss関数
を以下のようにします。
・は強いData Augmentation
・は上記で記載した方法で決定された疑似ラベル
・は閾値
- 全体のLoss関数は
となります。
[論文] FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
[2001.07685] FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
その他
半教師あり学習で気になっていた関連事項について少し調べました。
VAT
VAT(Virtual Adversarial Training)とは、ラベル分布を滑らかにすることによって、半教師あり学習で正則化を行う方法です。
- ラベルなしデータ
のモデルの出力値 (推測ラベル)と、そのデータに摂動
を加えたデータのモデルの出力値 の 2 つの分布の差異を以下のように表し、正則化項とします。
・は非負の差異の値を返す関数でクロスエントロピーなどです
・ 摂動は2つの分布の差異がもっとも大きくなる摂動です。(ただし
で
はハイパラ )
- 上記の
を使ってLoss関数を以下のように定めます。
・はラベルつきデータのクロスエントロピーLoss。
・はそれぞれ、ラベル付きデータ数とラベルなしデータ数

この図は、半教師あり学習でVATを用いた時のモデルの予測値(上段)と、LDSの値 (下段)のシミュレーションです。緑とピンクがそれぞれのラベルの値で、グレーがラベルが付いていないデータです。
境界部分が徐々に良くなっているのがわかります。
[論文] Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
[1704.03976] Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
UDA
UDA (Unsupervised Data Augmentation) は、ラベルなしデータに Data Augmentation をかけたデータ のモデル出力値
と、変換しなかったラベルなしデータ
のモデル出力値
をなるべく同じにして学習する方法です。FixMatchのアイディアの元になった手法です。

最終的な目的関数は以下の通りで、図のSupervised Cross-entropy Loss が 1 項目で、 図の Unsupervised Consistency Loss が 2 項目です。
[論文] Unsupervised Data Augmentation for Consistency Training
[1904.12848] Unsupervised Data Augmentation for Consistency Training
RandAugment
RandAugmentとは、Data Augmentationの 1 つで自動で変換をかける手法です。
計算コストが低いことが特徴です。
- Data Augmentationの種類は以下のK(=14)種類からランダムに選ばれます。

- 強さの探索に関しては、パラメータの値をそれぞれ
の整数にスケーリングしておき、全てData Augmentationの変換で同じ値(スケーリング後の値が同じ)を使います。値の決め方は、ランダム・固定・線形増加・上限が増加していくランダムサンプリング、という4種類で実験し、どれも精度に大差なしとのこと。
[論文] RandAugment: Practical automated data augmentation with a reduced search space
[1909.13719] RandAugment: Practical automated data augmentation with a reduced search space
kaggleで強化学習をやってみた
概要
現在、kaggle に Connect X という強化学習の Getting Started コンペ があります。このコンペを通じて強化学習を少し勉強したので、その内容を記載したいと思います。
こちらの書籍をもとに強化学習について理解したことと、Connect Xコンペでの実装を解説した記事になります。間違いがあれば、コメントいただけたら嬉しいです。
強化学習とは
強化学習とは、行動から報酬が得られる環境において、各状況で報酬に繋がるような行動を出力するように、モデルを作成すること。
教師あり学習との違いは連続した行動によって得られる報酬を最大化させるという点です。囲碁を考えた時、ある局面で悪手に見えた一手が、先々進めると実は良い手だった、といった場合のその一手を選択できるようにするのが強化学習になります。
Connect X と強化学習
いわゆる四目並べゲームです。対戦相手より先に、自分のピースを縦・横・斜めのいずれかで、4つ揃えられたら勝ちになります。

提出するファイルは通常のようなcsvファイルではなく、エージェントの振る舞いが記載されているPythonファイルを提出します。
Connect X のルールをふまえ、強化学習での考えを整理します。
エージェント
四目並べを行うプレーヤー
行動 Action
ピースを入れること
ConnectXでは、ピースは「チェッカー」、列を選ぶことを「ドロップ」と表現。
状態 State
ゲームボード上のチェッカーの配置。
(以降の記載では、 が現在の状態、
が次のSTEPの状態と表している)
報酬 Reward
ゲーム終了時に勝つと 1 が、負けると 0 が、どちらでもない場合 (引き分け・勝負がついていない) だと 0.5 が報酬として得られます。
行動後すぐに得られる報酬を即時報酬と呼びます。
また、時間割引された報酬の総和を以下のように表します。
は時間 (手/ステップ)、
が時間割引率
10手で勝利した場合と、 20手で勝利した場合では、前者の方がより良いものと評価したいため。
これは再帰的に表すことが可能。
報酬関数 Reward Function
報酬を返す関数。
遷移関数 Transition Function
現在の状態と行動から、ある状態になる確率と、遷移先を返す関数。
遷移関数が状態遷移確率 を出力し、遷移先は状態遷移確率の高いものとなる。
Connect X では、ゲーム上選択可能なActionをした場合、必ず想定通りの状態に遷移するので考慮しないものとします。
戦略 Policy
ある状態 で次の行動
を決める関数。
遷移関数と似ていますが、Policyは実際に起こす行動を決めるもので、その行動を起こすとどのような状態になるのかを定めているのが遷移関数です。
強化学習の種類
モデルベース
遷移関数と報酬関数をベースに学習することをモデルベースといいます。
ある状態 で戦略
に基づいて行動することで得られる価値
を、以下のように表すことができます。
期待値 は、行動確率 (戦略から決まる) と遷移確率をかけることで導き出すことができます。
価値が最大になるような行動を常に選択する方法を Value ベースといい、行動の評価方法のみを学習します。それとは別に、戦略によって行動を決定し、その戦略の評価と更新に行動評価を使う方法を Policy ベースといいます。
上記の式において、次のSTEPにおける価値 が計算済みでないといけないわけですが、全ての行動に対する価値を計算するのはパターンが多い場合は容易ではないため、動的計画法 DP が用いられます。
モデルベースではエージェントが一歩も動くことなく、環境の情報のみで最適な計画 (戦略) を導くことができます。ただし、これは遷移関数と報酬関数が既知 (もしくは推定が可能) である必要があります。そのため、一般的にはモデルベースではなくモデルフリーが使われます。今回の Connect X でもモデルフリーでのアプローチになるため、モデルベースの詳細については割愛します。
モデルフリー
エージェントが自ら動き、その経験を使って学習することをモデルフリーといいます。
経験とは、見積もっていた価値 と、実際に行動してみた時の価値
の差分のことです。
代表的なものに、モンテカルロ法とTD法があります。TD法は1STEP進んだら、誤差 (TD誤差) を小さくする更新を行い、モンテカルロ法はエピソード終了までSTEPを進めてから、誤差を小さくする更新を行います。
TD法の の更新の仕方
モンテカルロ法の の更新の仕方
TD法の代表的なものにQ-learningがあります。ある状態におけるある行動をすることの価値を と表しQ値と言います。Q-learningは戦略を使用せずに、価値が最大となる状態に遷移する行動をとり、価値評価を更新するため Off-Policy (戦略がない)と言います。これに対し、SARSAという方法は行動の決定が戦略に基づくものであり、戦略を更新するため、On-Policy と言います。戦略をActorが担当し、価値評価をCriticが担当して交互に更新を行うActor Critic法というものもあります。
Connect X
強化学習について大まかに理解したところで、Connect X の環境を触ってみたいと思います。
インストール
ConnectX コンペの環境が使えるよう、以下のライブラリをインストールします。
>> pip install kaggle-environments
ライブラリの使い方
make でゲーム環境のインスタンを生成し、render で ゲームボードの状態を表示することができます。
from kaggle_environments import make, utils env = make("connectx", debug=True) env.render()

configuration に、ゲームの構成情報があります。列が 7 で行が 6 のボードでチェッカーを 4 つ揃えたら良いことがわかります。
print(env.configuration) >> {'timeout': 5, 'columns': 7, 'rows': 6, 'inarow': 4, 'steps': 1000}
エピソードが終了すると、done が True を返します。
対戦相手をランダムとして、トレーナーを作成し、ゲームを初期化 (リセット) し、毎回 0 列目にドロップしてみます。
trainer = env.train([None, "random"]) state = trainer.reset() print(f"board: {state.board}\n"\ f"mark: {state.mark}") while not env.done: state, reward, done, info = trainer.step(0) print(f"reward: {reward}, done: {done}, info: {info}") board = state.board env.render(mode="ipython", width=350, height=300)
>> board: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
>> mark: 1
>> reward: 0.5, done: False, info: {}
>> reward: 0.5, done: False, info: {}
>> reward: 0.5, done: False, info: {}
>> reward: 1, done: True, info: {}
- state.board には、ボード上の配置がシリアル化された配列が得られます
- state.mark で自分のチェッカーが 1 か 2 か判別できます
- trainer.step() に自分がドロップする列を渡すと、相手もドロップした後の state とreward 、ゲームの終了判定フラグが得られます
- すでに6つチェッカーが配置されている列にドロップすると、Invalid Action となり reward Nan でゲーム終了となります
- renderのmode を ipython にすると jupyter notebook 上でプレイ動画の再生ができます

評価指標
ガウス分布 でモデル化され、
の値がスキル評価としてLBに反映されています。サブミットすると、
は 600で初期化されて、全エージェントのプールに入れられます。各エージェントは 1 日最大 8 エピソード分、自分の評価と近しいものと対戦を行います。その対戦で負けると
の値が小さくなり、勝つと
の値が大きくなり、引き分けだと両者の平均となります。値の更新は、それぞれの偏差を考慮した値になり
も更新されます。また、新しいエージェントの場合は、レートを少し上げて出来るだけ早く、適切な値になるように調整しているそうです。
新たなエージェントを作成したとき、サブミット前に現在のLBのおける 値の計算をするのは難しいですが、いずれにせよ、強いエージェントは徐々に LB を登っていき、負け続けると下がっていくようになっています。
エージェントの作成
Connect X コンペでは、エージェントの振る舞いが記載された Python ファイルを提出する必要があるので、エージェントを作成して提出してみます。
一番上が 0 (空) である列の中から、ランダムに 1 つ選ぶだけのエージェントを作成します。
from random import choice def my_agent(state, configuration): return choice([c for c in range(configuration.columns) if state.board[c] == 0])
evaluate に、ゲーム名とエージェントとエピソード数を渡すと、対戦結果が得られます。
以下の出力だと 2 勝 1 敗です。
from kaggle_environments import evaluate print(evaluate("connectx", [my_agent, "random"], num_episodes=3)) >> [[1, 0], [0, 1], [1, 0]]
submission.py ファイルに my_agent を出力します。
import inspect import os def write_agent_to_file(function, file): with open(file, "a" if os.path.exists(file) else "w") as f: f.write(inspect.getsource(function)) write_agent_to_file(my_agent, "submission.py")
これは提出ファイルのエージェントが正常に動作するかの確認コードです。サブミットする前に、確認しておきます。
import sys out = sys.stdout submission = utils.read_file("{提出ファイルPath}") agent = utils.get_last_callable(submission) sys.stdout = out env = make("connectx", debug=True) env.run([agent, agent]) print("Success" if env.state[0].status == env.state[1].status == "DONE" else "Failed") >> Success
ファイルが出力されたら、いつもと同じようにファイルをアップロードします。
通常と同じく、kernelから提出することも、APIで提出することもできます。

LB上のディスプレイアイコンをクリックすると、LB上での対戦動画がみれます!このような他のコンペとは違うところは、面白いですね。
Q-Learning の実装
ある状態である行動を行うことの価値をQ値 と表し、そのQ値を学習する方法である、Q-Learning を Connect X に用に実装してみます。
Qテーブル
Q値を格納しておくQテーブルの実装
- Q : Qテーブルをdictで、keyに状態を, valueに全actionのQ値を配列で格納しておく
- get_state_key : Qテーブルのkeyである、状態 (自分がどちらのチェッカーかも加味) を state_key (16進数)で表す
- get_q_values : ある状態での全actionのQ値を配列 (0 ~ 6: ドロップする列順) で返す関数
- update : ある状態におけるあるアクションに対して更新をかける
class QTable(): def __init__(self, actions): self.Q = {} # Qテーブル self.actions = actions def get_state_key(self, state): # 16進数で状態のkeyを作る board = state.board[:] board.append(state.mark) state_key = np.array(board).astype(str) return hex(int(''.join(state_key), 3))[2:] def get_q_values(self, state): # 状態に対して、全actionのQ値の配列を出力 state_key = self.get_state_key(state) if state_key not in self.Q.keys(): # 過去にその状態になったことがない場合 self.Q[state_key] = [0] * len(self.actions) return self.Q[state_key] def update(self, state, action, add_q): # Q値を更新 state_key = self.get_state_key(state) self.Q[state_key] = [q + add_q if idx == action else q for idx, q in enumerate(self.Q[state_key])]
Agent の実装
- policy function : Qテーブルをもとに、ある状態におけるQ値が最大なactionを選択する
- custom_reward : Qテーブルの作成がよりうまくいくように報酬関数をカスタマイズ
- learn : エピソードごとにQテーブルを更新して学習させる
- q_table : 状態 x 行動 に対して、価値を格納しおく Q テーブル
- reward_log : 報酬の履歴
パラメータ
- episode_cnt : 学習に使うエピソード数
- epsilon : 探索を行う(Q値に従わない)ようにする確率, はじめは大きくて徐々に小さくなるように実装
- gamma : 時間割引率
- learn_rate : 学習率
env = make("connectx", debug=True) trainer = env.train([None, "random"]) class QLearningAgent(): def __init__(self, env, epsilon=0.99): self.env = env self.actions = list(range(self.env.configuration.columns)) self.q_table = QTable(self.actions) self.epsilon = epsilon self.reward_log = [] def policy(self, state): if np.random.random() < self.epsilon: # epsilonの割合で、ランダムにactionを選択する return choice([c for c in range(len(self.actions)) if state.board[c] == 0]) else: # ゲーム上選択可能で、Q値が最大なactionを選択する q_values = self.q_table.get_q_values(state) selected_items = [q if state.board[idx] == 0 else -1e7 for idx, q in enumerate(q_values)] return int(np.argmax(selected_items)) def custom_reward(self, reward, done): if done: if reward == 1: # 勝ち return 20 elif reward == 0: # 負け return -20 else: # 引き分け return 10 else: return -0.05 # 勝負がついてない def learn(self, trainer, episode_cnt=10000, gamma=0.6, learn_rate=0.3, epsilon_decay_rate=0.9999, min_epsilon=0.1): for episode in tqdm(range(episode_cnt)): # ゲーム環境リセット state = trainer.reset() # epsilonを徐々に小さくする self.epsilon = max(min_epsilon, self.epsilon * epsilon_decay_rate) while not env.done: # どの列にドロップするか決めるて実行する action = self.policy(state) next_state, reward, done, info = trainer.step(action) reward = self.custom_reward(reward, done) # 誤差を計算してQテーブルを更新する gain = reward + gamma * max(self.q_table.get_q_values(next_state)) estimate = self.q_table.get_q_values(state)[action] self.q_table.update(state, action, learn_rate * (gain - estimate)) state = next_state self.reward_log.append(reward)
結果
# 学習 qa = QLearningAgent(env) qa.learn(trainer) # ゲーム終了時に得られた報酬の移動平均 import seaborn as sns sns.set(style='darkgrid') pd.DataFrame({'Average Reward': qa.reward_log}).rolling(500).mean().plot(figsize=(10,5)) plt.show()
更新された q_table に学習で得られた Q 値が、 reward_log に報酬の履歴 (勝敗) が得られます。
報酬の移動平均をみると、徐々に勝率が上がっているのが確認できます。ちゃんと学習できているようです!

Pythonファイルへの出力
また、エージェントの振る舞いをする1つの関数としてPythonファイルへ出力するため、Qテーブルのデータを文字列に変換し、以下のコードでPythonファイルに書き込む際にdictとして扱えるようにして出力します。
tmp_dict_q_table = qa.q_table.Q.copy() dict_q_table = dict() # 学習したQテーブルで、一番Q値の大きいActionに置き換える for k in tmp_dict_q_table: if np.count_nonzero(tmp_dict_q_table[k]) > 0: dict_q_table[k] = int(np.argmax(tmp_dict_q_table[k])) my_agent = '''def my_agent(observation, configuration): from random import choice # 作成したテーブルを文字列に変換して、Pythonファイル上でdictとして扱えるようにする q_table = ''' \ + str(dict_q_table).replace(' ', '') \ + ''' board = observation.board[:] board.append(observation.mark) state_key = list(map(str, board)) state_key = hex(int(''.join(state_key), 3))[2:] # Qテーブルに存在しない状態の場合 if state_key not in q_table.keys(): return choice([c for c in range(configuration.columns) if observation.board[c] == 0]) # Qテーブルから最大のQ値をとるActionを選択 action = q_table[state_key] # 選んだActionが、ゲーム上選べない場合 if observation.board[action] != 0: return choice([c for c in range(configuration.columns) if observation.board[c] == 0]) return action ''' with open('submission.py', 'w') as f: f.write(my_agent)
Qテーブルの作り方・ファイル出力の仕方はこちらのkernelを参考にしました.
ConnectX with Q-Learning | Kaggle
Deep Q-Net の実装
強化学習にディープラーニングを使った代表的なDeep Q-Netについて、Connect X 用に実装してみます。
基本的な考え方はQ-learningと同じで、Qテーブルで行なっていた価値の評価に、CNNを用います。
inputは状態 で、outputはactionの価値で、Loss関数でTD誤差を最小化するするように実装します。
また、うまく学習を行うための 3 つのテクニックがあります。
Experience Replay
エージェントの行動履歴を貯めておき、そこからサンプリングして学習に利用します。行動履歴とは [ 状態, 行動, 報酬, 遷移先の状態, エピソードの終了フラグ ] のまとまりになります。さまざまなエピソードの異なるタイミングのデータが使えることで、学習を安定させることができます。
Fixed Target Q-Network
遷移先の価値を計算する場合、現在の更新しているモデル(CNN)と同じものを使用すると重みを更新するたびに違った値になってしまい、TD誤差が安定しないものになってしまいます。一定期間、更新していないCNNモデルから遷移先の価値を計算し、あるタイミングで更新をかける、といった方法をとります。価値の評価のために更新し続けているCNNと遷移先の価値計算用のCNN、2 つを使って学習します。
Clipping
報酬を、成功が 1 , 失敗が -1 , それ以外は 0 に統一します。
CNN の実装
価値評価を行うためのCNNを実装します。上記、Fixed Target Q-Network を使うため、価値評価用のCNNと遷移先価値計算用のCNN、両方このCNNを使います。
今回は、四目並べという小さいゲームボードなので、ネットワーク構成を畳み込み2層の小さいCNNにしてみました。input は状態のゲームボードのチェッカーの配置を2次元 (7, 6) でそのまま入れてます。output は action の value (7) です。
import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F class CNN(nn.Module): def __init__(self, outputs=7): super(CNN, self).__init__() self.conv1 = nn.Conv2d(1, 16, 3) self.bn1 = nn.BatchNorm2d(16) self.conv2 = nn.Conv2d(16, 32, 3) self.bn2 = nn.BatchNorm2d(32) self.fc = nn.Linear(192, 32) self.head = nn.Linear(32, outputs) def forward(self, x): x = F.relu(self.bn1(self.conv1(x))) x = F.relu(self.bn2(self.conv2(x))) x = x.view(x.size()[0], -1) x = self.fc(x) x = self.head(x) return x
Deep Q-Net の Agent の実装
エージェントの実装をします。Q-lerningでの実装の違いは、以下の 4 点です。
- 見積もり価値と、実際に行動価値の誤差(TD誤差)を最小化するところをCNNにする
- CNNに入れられるように、チェッカーの配置を (1, 7, 6) の Tensorに変換するところと
- 自分のチェッカーを 1 、相手のチェッカーを 0.5 に したこと
- 上記のテクニック Experience Replay, Fixed Target Q-Network, Clipping を使用すること
class DeepQNetworkAgent(): def __init__(self, env, lr=1e-2, min_experiences=100, max_experiences=10_000, channel=1): self.env = env self.model = CNN() # 価値評価用のCNN self.teacher_model = CNN() # 遷移先価値評価用のCNN self.optimizer = optim.Adam(self.model.parameters(), lr=lr) self.criterion = nn.MSELoss() self.experience = {'s': [], 'a': [], 'r': [], 'n_s': [], 'done': []} # 行動履歴 self.min_experiences = min_experiences self.max_experiences = max_experiences self.actions = list(range(self.env.configuration.columns)) self.col_num = self.env.configuration.columns self.row_num = self.env.configuration.rows self.channel = channel def add_experience(self, exp): # 行動履歴の更新 if len(self.experience['s']) >= self.max_experiences: # 行動履歴のサイズが大きすぎる時は古いものを削除 for key in self.experience.keys(): self.experience[key].pop(0) for key, value in exp.items(): self.experience[key].append(value) def preprocess(self, state): # 状態は自分のチェッカーを1, 相手のチェッカーを0.5とした7x6多次元配列で表す result = np.array(state.board[:]) result = result.reshape([self.col_num, self.row_num]) if state.mark == 1: return np.where(result == 2, 0.5, result) else: result = np.where(result == 2, 1, result) return np.where(result == 1, 0.5, result) def estimate(self, state): # 価値の計算 return self.model( torch.from_numpy(state).view(-1, self.channel, self.col_num, self.row_num).float() ) def future(self, state): # 遷移先の価値の計算 return self.teacher_model( torch.from_numpy(state).view(-1, self.channel, self.col_num, self.row_num).float() ) def policy(self, state, epsilon): # 状態から、CNNの出力に基づき、次の行動を選択 if np.random.random() < epsilon: # 探索 return int(np.random.choice([c for c in range(len(self.actions)) if state.board[c] == 0])) else: # Actionの価値を取得 prediction = self.estimate(self.preprocess(state))[0].detach().numpy() for i in range(len(self.actions)): # ゲーム上選択可能なactionに絞る if state.board[i] != 0: prediction[i] = -1e7 return int(np.argmax(prediction)) def update(self, gamma): # 行動履歴が十分に蓄積されているか if len(self.experience['s']) < self.min_experiences: return # 行動履歴から学習用のデータのidをサンプリングする ids = np.random.randint(low=0, high=len(self.experience['s']), size=32) states = np.asarray([self.preprocess(self.experience['s'][i]) for i in ids]) states_next = np.asarray([self.preprocess(self.experience['n_s'][i]) for i in ids]) # 価値の計算 estimateds = self.estimate(states).detach().numpy() # 見積もりの価値 future = self.future(states_next).detach().numpy() # 遷移先の価値 target = estimateds.copy() for idx, i in enumerate(ids): a = self.experience['a'][i] r = self.experience['r'][i] d = self.experience['done'][i] reward = r if not d: reward += gamma * np.max(future[idx]) # TD誤差を小さくするようにCNNを更新 self.optimizer.zero_grad() loss = self.criterion(torch.tensor(estimateds, requires_grad=True), torch.tensor(target, requires_grad=True)) loss.backward() self.optimizer.step() def update_teacher(self): # 遷移先の価値の更新 self.teacher_model.load_state_dict(self.model.state_dict())
Deep Q-Net の Trainer の実装
基本的に、Q-learning と変わりません。
行動履歴をためていく処理と、一定の間隔で価値評価用のCNNのパラメータを遷移先価値計算用のCNNにコピーしている処理が追加されています。
class DeepQNetworkTrainer(): def __init__(self, env): self.epsilon = 0.9 self.env = env self.agent = DeepQNetworkAgent(env) self.reward_log = [] def custom_reward(self, reward, done): # Clipping if done: if reward == 1: # 勝ち return 1 elif reward == 0: # 負け return -1 else: # 引き分け return 0 else: return 0 # 勝負がついてない def train(self, trainer,epsilon_decay_rate=0.9999, min_epsilon=0.1, episode_cnt=100, gamma=0.6): iter = 0 for episode in tqdm(range(episode_cnt)): rewards = [] state = trainer.reset() # ゲーム環境リセット self.epsilon = max(min_epsilon, self.epsilon * epsilon_decay_rate) # epsilonを徐々に小さくする while not env.done: # どの列にドロップするか決める action = self.agent.policy(state, self.epsilon) prev_state = state state, reward, done, _ = trainer.step(action) reward = self.custom_reward(reward, done) # 行動履歴の蓄積 exp = {'s': prev_state, 'a': action, 'r': reward, 'n_s': state, 'done': done} self.agent.add_experience(exp) # 価値評価の更新 self.agent.update(gamma) iter += 1 if iter % 100 == 0: # 遷移先価値計算用の更新 self.agent.update_teacher() self.reward_log.append(reward)
結果
実際に Deep Q-Net Agentで学習してみます。
dq = DeepQNetworkTrainer(env) dq.train(trainer, episode_cnt=30000) # 結果の描画 import seaborn as sns sns.set() sns.set_palette("winter", 8) sns.set_context({"lines.linewidth": 1}) pd.DataFrame({'Average Reward': dq.reward_log}).rolling(300).mean().plot(figsize=(10,5))

報酬の履歴から勝敗の移動平均をみてみると、徐々に勝てるようになっていて、うまく学習できていそうです。(さきほどのQ-learningとは報酬関数が異なるので、y軸のスケールが異なります)
今回、20,000エピソード学習させましたが、他の方のkernelを見ると3000エピソードぐらいでうまく学習させられている人もいるので、CNNやパラメータを調整して上手く早く学習できるように工夫した方が良いのかもしれません。
おわり
強化学習初心者の勉強の場として、kaggle の Connect X は最適だと思いました!kaggle の notebook を立ち上げればすぐにエージェントを動かせる環境が整うのはとても便利です。学習済みエージェントをどう記載するかという悩ましい問題はあるのですが(外部ファイルの読み込み、学習したモデルの読み込みができない)、Getting Started コンペなので、気軽に参加できて楽しかったです。
Connect X の実装がメインになり、強化学習の理論についてはまだ勉強不足なので、引き続き学んでいきたいです。
勉強会のお知らせ
Wantedly では毎週木曜日18:30から機械学習の勉強会を開いていますが、現在、社員が原則リモートワークのためオンライン (hangouts) で開催しています!オンラインだからこそ参加しやすいかと思いますので、興味がある方は、是非!
また、カジュアル面談 (現在オンライン)・インターンも募集しています!
www.wantedly.com
Kaggle Google QUEST Q&A コンペ 振り返り
はじめに
Kaggleで開催されていた Google QUEST Q&A Labeling Competition 、通称 QUEST コンペ、QA コンペに参加したので、コンペの概要を記載します。また、このコンペで、 78位 / 1579チーム中でギリギリ銀メダルを獲得できたので、取り組んだことを記載します。

コンペの概要
英文による質問と回答のペアが与えられており、そのペアに対する30項目における評価値 ( ] )を予測します。
質問タイトルや質問者・回答者の名前、サイトURLやカテゴリーもデータとして提供されていました。
この30項目はとても主観的な内容であり、コンピュータでは評価が困難なQAに対する主観的評価を行うことが今回のコンペの意義のようです。
| url | http://stats.stackexchange.com/questions/125/what-is-the-best-introductory-bayesian-statistics-textbook |
| カテゴリ | SCIENCE |
| 質問者 | Shane |
| 回答者 | gappy |
| 質問 タイトル | What is the best introductory Bayesian statistics textbook? |
| 質問 本文 | Which is the best introductory textbook for Bayesian statistics? One book per answer, please. |
| 回答 | "Bayesian Core: A Practical Approach to Computational Bayesian Statistics" by Marin and Robert, Springer-Verlag (2007) |
| 評価項目 1 質問の意図が理解できる |
1.0 |
| |
|
| 評価項目 30 回答が上手く書かれてる |
1.0 |
Notebook Competition
QUEST コンペは Kaggle Notebook のみのコンペでした。予測結果を submission.csv というファイルで出力するようなコードを Notebook に記載して提出します。トレーニング済みのモデルをデータセットとしてアップロードして使うことが許可されていたため、実質は推論のみを Kaggle Notebook 上で実行すればOKでした。
また、Internet は Off でないといけないため、外からデータをダウンロードすることはできませんでした。
他のNotebook コンペと同様、GPUの場合は2時間、CPUの場合は9時間の時間制限があります。
しかし、時間制限よりもソロ参加者にとっては、Private Datasetの容量制限が 20GBというのがちょっと苦しかったです。
評価関数
このコンペの評価関数はスピアマン順位相関係数でした。
正解データと予測値のランクの類似度を表した値になります。
は正解データと予測データのランキングの差になります。 (あるデータで、正解が10位、予測が9位なら
は 1)
データの特徴
Training データの数は6079, PublicになってるTest データの数は476です。
Training データと Test データのデータ提供元 (host名) の割合です。
両方とも20%強が stack overflowからで、それ以外はどれも5%未満です。


カテゴリの割合は Training データと Test データはほぼ同じです。


また、正解データを見ると離散値であることが確認できます。
(30項目中10個をピックアップ)

Start From Here : QUEST Complete EDA + FE ✓✓ | Kaggle
正解データが離散値であり、ほとんどが循環小数であることから何人かのアノテータが各項目を0, 1で評価し、その平均値を正解データとしたようです。また、その循環小数を見ることで何人のアノテータがいたかが、おおよそわかります。
取り組んだこと
モデル
BERT, XL-Net, RoBERTa の平均です。
Transformers の BertForSequenceClassification はヘッドが以下のようになっているので、config の num_labels にクラス数 ( 評価項目の数 ) を指定して、事前学習済みモデルを Fine-tuning して利用しました。
( XL-Net, RoBERTaも同じ)
class BertForSequenceClassification(BertPreTrainedModel): def __init__(self, config): super().__init__(config) self.num_labels = config.num_labels self.bert = BertModel(config) self.dropout = nn.Dropout(config.hidden_dropout_prob) self.classifier = nn.Linear(config.hidden_size, self.config.num_labels) self.init_weights()
transformers/modeling_bert.py at master · huggingface/transformers · GitHub
モデルを上手に改良してスコアを上げられたら良かったのですが、色々試みたものの全く良くなりませんでした。
評価項目ごとにモデルを作成
評価項目を以下の3つに主観で分類しました。
- 1. 質問文のみで評価できる (例えば「質問の意図が理解できる」)
- 2. 回答文のみで評価できる (例えば「回答が構造的に書かれているか」)
- 3. 質問文と回答文揃ってないと評価ができない(例えば「回答が尤もらしいか」)
また、ぞれぞれ以下のように学習しました。
- 1. に分類される評価項目は、インプットを質問文と質問タイトルを結合したもので学習
- 2. に分類される評価項目は、インプットを回答文のみで学習
- 3. に分類される評価項目は、インプットを質問文と質問タイトルと回答文を結合したもので学習
前処理
基本的にTransformersのTokenizerがよしなにやってくれるので、stop word や省略形などの対応はしませんでした。
BERTを使う上で必要な special token に変換される、[CLS]や[SEP]などを結合することや attention mask を作成することなどはしました。
後処理
データの特徴で記載したとおり、正解データが離散値で評価関数がスピアマン順位相関係数であることから出力された値を、クラスタリングしてまとめて同じ値に変換する後処理をしました。
例えば、[question_type_instructions] という評価項目なら、ヒストグラムを描くとこのような予測値なのですが

以下のように近い値を同じ値に変換するということです。

クラスタリングは scikit-learn の BayesianGaussianMixture を使いました。
from sklearn.mixture import BayesianGaussianMixture dp = BayesianGaussianMixture(18) pred = dp.fit_predict(sub[col].values.reshape(-1, 1))
CV結果をみて、実際に変換する評価項目を以下の 3 つにしました。
- question_has_commonly_accepted_answer
- question_type_consequence
- answer_plausible
また、Training データからアノテーターの人数を推測し、想定される離散値に予測値を寄せるという対応も行いました。離散値どうしの中間の値を閾値にして、どちらに近いかで寄せる値を決めました。
CV結果をみて、実際に変換する評価項目を以下の 4 つにしました。
- question_conversational
- question_type_compare
- question_type_definition
- question_type_entity
学習時のパラメータ
- loss: BCEWithLogitsLoss
- optimizer: AdamW
- lr: 3e-5
- Batch Size: 8
- 5-fold
その他
BERTとNLPライブラリのTransformersの使い方を学びました。
( BERTは完全理解というより、お気持ち理解程度です。)
Transformerの論文 : [1706.03762] Attention Is All You Need
BERTの論文 : [1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Transformersのライブラリ: Transformers — transformers 2.4.1 documentation
まつけん (@Kenmatsu4) | Twitterさんの資料 : BERT入門
Ryobotさんのブログ : 論文解説 Attention Is All You Need (Transformer) - ディープラーニングブログ
自然言語処理におけるEmbeddingの方法一覧とサンプルコード
Word2vec
似た意味の単語の周りには同じような単語が出現するとして、ある単語の周辺に出現する単語を予測するNNの隠れ層の重みを、ある単語のベクトルとしたもの。Doc2vecはWord2vecを文章に拡張したもの。
NNには以下のようなSkip-Gramのモデルが使われる。

Word2vecの元論文 : [1310.4546] Distributed Representations of Words and Phrases and their Compositionality
Doc2vecの元論文 : [1405.4053] Distributed Representations of Sentences and Documents
参考 1 : 絵で理解するWord2vecの仕組み - Qiita
参考 2 : [1411.2738] word2vec Parameter Learning Explained
サンプルコード
gensimを使います。ここから日本語のWikipediaの学習済みモデルをダウンロードしてきます。
学習済みモデル : GitHub - Kyubyong/wordvectors: Pre-trained word vectors of 30+ languages
import gensim model = gensim.models.Word2Vec.load('ja/ja.bin') print(model.wv['三日月'])
>> array([-1.61277249e-01, -3.04615557e-01, 2.59203255e-01, 2.29006037e-01, .....
5.58053315e-01, -3.36245120e-01], dtype=float32)fastText
Word2vecの単語の活用形 (subword) を考慮したもの。
元論文 :[1607.04606] Enriching Word Vectors with Subword Information
サンプルコード
facebook research のリポジトリにfasttextのソースコードと使い方があるのですが、今回は学習済みモデルから生成されたベクトル一覧ファイルから、ベクトルを取得しました。
ソースコード : GitHub - facebookresearch/fastText: Library for fast text representation and classification.
ワードベクトル : English word vectors · fastText
import io def load_vectors(target_word): fin = io.open('wiki-news-300d-1M.vec', 'r', encoding='utf-8', newline='\n', errors='ignore') for line in fin: tokens = line.rstrip().split(' ') if target_word == tokens[0]: return [float(s) for s in tokens[1:]] print(load_vectors('sun'))
>> [0.1882, 0.0284, -0.1026, 0.0115, -0.0426, -0.1592, 0.0543, 0.1111, -0.0036, -0.0481, 0.0463, 0.0837, ....
-0.0851, 0.1371, 0.1049, 0.0401, 0.0375, 0.0062, -0.0197, 0.0295, -0.0276]GloVe
GloVe (Global Vectors for Word Representation) は、文書全体における単語と単語の共起行列を使って表される、ある単語の文脈単語が現れる確率(に対数をとった)値と、ある単語ベクトルと文脈単語ベクトルの内積が等しいものとモデル化して、最小二乗法で解くことで得られるものを、ある単語のベクトルとしたもの。
元論文 : https://nlp.stanford.edu/pubs/glove.pdf
参考 : 論文メモ: GloVe: Global Vectors for Word Representation - け日記
サンプルコード
スタンフォードのサイトにある学習済みモデルから生成した単語ベクトルの一覧ファイルから、ベクトルを取得します。
ソースコード : GitHub - stanfordnlp/GloVe: GloVe model for distributed word representation
ワードベクトル : GloVe: Global Vectors for Word Representation
import numpy as np embeddings_dict = {} with open("glove.6B/glove.6B.50d.txt", 'r') as f: for line in f: values = line.split() word = values[0] vector = np.asarray(values[1:], "float32") embeddings_dict[word] = vector embeddings_dict['water']
>> array([ 0.53507 , 0.5761 , -0.054351, -0.208 , -0.7882 , -0.17592 ,.....
0.61563 , -0.95478 ], dtype=float32) Skip-thought
Skip-thought は、ある文章 (単語をone-hot) をエンコーダーの入力とし、その文章の前の文章と、後の文章をそれぞれデコーダーの出力として学習させたNNにおいて、エンコーダーの入力となるある文章の最後の単語が入力された次の時点の隠れ層の出力値が、文章ベクトルとして得られる。エンコーダーとデコーダーには GRU ベースの RNN モデルを使用。
下の図で言うところの、点線で囲われている部分が得られる文章ベクトル。

元論文 : [1506.06726] Skip-Thought Vectors
参考 : Skip-thoughtを用いたテキストの数値ベクトル化 - Platinum Data Blog by BrainPad
SCDV
SCDV (Sparse Composite Document Vectors) は、以下のように文章のベクトルを得る。
1. Word2vecなどで、単語ベクトルを得る
2. GMMでK個のクラスタに分ける
3. 1.の単語ベクトルと2.の単語がクラスタに属する確率から、単語クラスタ表現を得る
4. 単語クラスタ表現に単語のidfと単語クラスタ表現を掛け合わせて、単語トピックベクトルを得る
5. 文章内の単語トピックベクトルを足し合わせる
6. ベクトル内の絶対値がゼロに近い要素をゼロとする
元論文 : [1612.06778] SCDV : Sparse Composite Document Vectors using soft clustering over distributional representations
参考 1 : 文章の埋め込みモデル: Sparse Composite Document Vectors を読んで実装してみた - nykergoto’s blog
参考 2 : [論文メモ] SCDV : Sparse Composite Document Vectors using soft clustering over distributional representations - Qiita
USE
USE (Universal Sentence Encoder) は、エンコーダーにTransformerを用いたNNで、前後文の予測や文書分類などの複数のタスクを解くことで得られる文章ベクトル。以下の図のようなNNで、グレーの部分は共通のエンコーダーレイヤーになっている。TransformerについてはBERTの説明欄を参照。
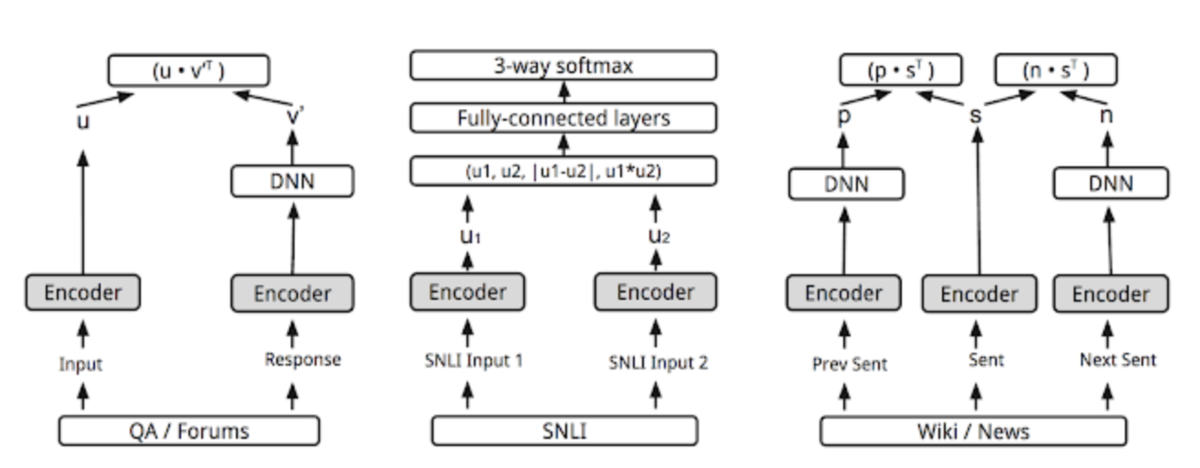
(TransformerではなくてDeep Averaging Network のものもある)
元論文 : [1803.11175] Universal Sentence Encoder
参考 1 : Universal Sentence Encoder · Issue #4 · hakubishin3/papers · GitHub
参考 2 : Google AI Blog: Advances in Semantic Textual Similarity
サンプルコード
TensorFlow Hub に事前学習済みUSEがあるので、それを使います。
https://tfhub.dev/google/universal-sentence-encoder/4
import tensorflow_hub as hub embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4") embeddings = embed(['It takes a great bravery to stand up to out enemies, but just as much to stand up to our friends.']) print(embeddings)
>> tf.Tensor([[-6.44176304e-02 -3.21280882e-02 -2.36084983e-02 5.24843968e-02 ......
1.38827525e-02 1.35980593e-03 -6.22187331e-02 2.80580819e-02]], shape=(1, 512), dtype=float32) ELMo
bi-LSTM(双方向LSTM)を複数層重ねたモデルで、各隠れ層の重みづけ線形和を Embedding ベクトルとして得る。前の単語列から1つ先の単語出現率を条件付き確率で表した時の対数尤度と、先の単語列から1つ前の単語出現率を条件付き確率で表した時の対数尤度を最大にするように学習する。利用するときは、入力の埋め込みベクトルと結合する必要がある。

元論文 : [1802.05365] Deep contextualized word representations
参考 : 論文メモ:Deep contextualized word representations – きままにNLP – A Technical Blog about NLP and ML
サンプルコード
AllenNLP を使います。
AllenNLP
from allennlp.modules.elmo import Elmo, batch_to_ids options_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_options.json" weight_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5" elmo = Elmo(options_file, weight_file, 2, dropout=0) sentences = ['By working faithfully eight hours a day, you may eventually get to be a boss and work twelve hours a day.'.split(' ')] character_ids = batch_to_ids(sentences) embeddings = elmo(character_ids) print(embeddings['elmo_representations'])
>> [tensor([[[ 0.2935, 0.2494, -0.4810, ..., -0.2546, -0.2394, 0.2540], ....
[-0.0577, 0.8521, -0.3685, ..., 0.0323, -0.1151, 0.2783]]], grad_fn= CopySlices )]BERT
双方向のTransformerを複数層重ねたモデルで、マスク予測と文脈の関連予測のタスクで学習させたもの。エンコーダーとして使うときは双方向Transformerを使い、言語生成をするときなどデコーダーとして使うときは単方向Transformerでデコードする。

元論文 : [1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
参考 : 作って理解する Transformer / Attention - Qiita
Transformerは、エンコーダーをマルチヘッドSelf-AttentionとFFNのブロックを複数重ねたもので、デコーダーをマルチヘッドSelf-AttentionとマルチヘッドSource-Target-AttentionとFFNのブロックを複数重ねたもので構成されたもの。

Self-Attentionは前の隠れ層をquery, key, value として(全て同じ)、queryとkeyの内積をsoftmaxに通したものとvalueの行列積をとったもの。Source-Target-Attentionは、queryがデーコーダーの隠れ層で、key, valueがエンコーダの隠れ層としたもので、同じくqueryとkeyの内積をsoftmaxに通したものとvalueの行列積をとったもの。
マルチヘッドにするには、query, key, value をそれぞれヘッドの数に分割して、それぞれで Attention を計算し、結果を結合する。

[1706.03762] Attention Is All You Need
論文解説 Attention Is All You Need (Transformer) - ディープラーニングブログ
サンプルコード
Transformersを使います。
Transformers — transformers 4.1.1 documentation
import torch from transformers import BertTokenizer, BertModel model = BertModel.from_pretrained('bert-base-uncased') tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') input_ids = torch.tensor(tokenizer.encode('The optimist sees the doughnut, the pessimist sees the hole.', add_special_tokens=True)).unsqueeze(0) outputs = model(input_ids) last_hidden_states = outputs[0] print(last_hidden_states)
>> tensor([[[-0.4030, 0.3356, -0.0636, ..., -0.6573, 0.6247, 0.6182], .....
[ 0.7766, 0.1315, -0.1458, ..., 0.1757, -0.4855, -0.3783]]], grad_fn=NativeLayerNormBackward)おわり
2ヶ月前ぐらいからNLPの勉強を始めたのですが、今までBERTとWord2vecぐらいしか知らなかったので、色々知れて良かったです。最近のNLPだとBERTに続き、ARBERTやDistil-BERT、XLNetが主要なモデルといったところでしょうか。この辺も引き続き調べていきたいです。
今回調べたどの方法も、とてもわかりやすいブログや記事が日本語で公開されていたため、理解するのにとても助かりました。それらを公開してくださった方々には感謝です!
また、誤りがありましたら指摘いただけたら嬉しいです。
宣伝
弊社にて毎週木曜日18:30から勉強会をやっているので、興味がある方は遊びに来ていただけたら嬉しいです !
github.com
また、データサイエンティスト職も募集中で、話だけでも聞きたいなどカジュアル面談も受け付けてます !
www.wantedly.com